近日,中国科大视觉与多媒体研究组提出基于边界增强协同训练的弱监督语义分割新方法,该方法结合提出的协同训练方式和边界增强策略来训练弱监督下的语义分割模型,有效提升了模型的鲁棒性和识别性能。相关成果以《Boundary-enhanced Co-training for Weakly Supervised Semantic Segmentation》为题,将发表在计算机视觉国际顶级会议CVPR2023上。
获取用于语义分割的精确像素级注释非常耗时和费力。为了减轻对像素级标注的高度依赖,提出了弱监督语义分割,它仅利用图像级类标签来执行像素级分类。这样的任务通常涉及两个训练阶段。在第一阶段,使用图像标签训练分类模型,然后用于生成类激活图,作为种子区域进一步扩展到伪标签。在第二阶段,生成伪标签作为像素级标签来训练分割模型。尽管现有的相关工作取得了不错的进展,但它们关注于弱监督语义分割的第一阶段,而忽略了第二阶段的重要性。本工作发现第一阶段中更好的伪标签质量并不能保证训练出性能更好的语义分割网络,所以提出了应该关注弱监督语义分割的第二阶段,解决第二阶段中的主要挑战,即伪标签噪声问题。
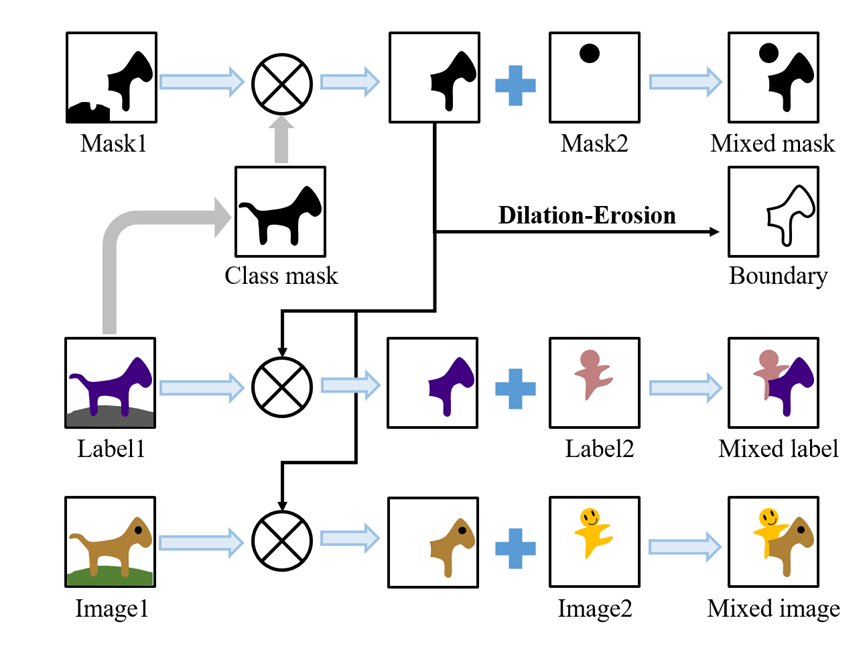
图1. 边界构造示意图
针对上述问题,本文提出边界增强的协同训练来实现分割模型的噪声鲁棒学习,通过使用两个交互式网络的协同训练范式来改进不确定像素的学习,以及一种边界增强策略来增强模型对困难边界区域的预测。具体地,在弱监督语义分割第一阶段获得伪标签和对应的置信掩码后,本文首先提出边界构造策略来构造边界已知样本。如图1所示,本文通过随机选择一张图像中的一半类别的高置信像素复制粘贴到另一张图像来获得边界已知的新样本。然后将原始的边界未知样本和构造的边界已知样本联合输入到分割网络中。为了减少伪标签噪声的影响,本文提出了协同训练的噪声鲁棒学习框架。如图2所示,整体框架由两个并行的网络构成,它们结构相同,但参数不共享且初始化不同。两个网络对图像的高置信像素使用伪标签监督,对图像的低置信像素使用另一个网络输出的在线伪标签进行监督。同时为了增强模型对边界区域的预测,该范式对边界已知图像中的边界像素赋予更大的损失权重。通过结合协同训练范式和边界增强策略,本工作有效增强模型的噪声鲁棒性和提升模型的语义分割性能,在两个公开的数据集上的语义分割指标都超过了现有的领先方法。
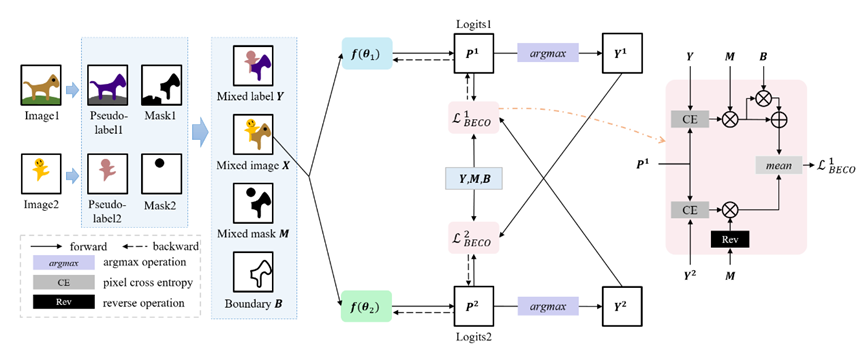
图2. 边界增强协同训练示意图
中国科学技术大学博士生容圣海为本工作的第一作者。中国科大视觉与多媒体研究组王子磊副教授为本工作的通讯作者,涂博海为本论文第二作者,在方案讨论、代码实现和实验运行方面提供了有力支持。李俊杰为该论文第四作者,在方案讨论上提供了宝贵的意见。该研究工作得到国家自然科学基金等项目的资助。
论文链接:待添加