近日,中国科大视觉与多媒体研究组的研究团队在弱监督的视频时序动作检测任务上取得进展。该研究团队发现在弱监督的视频时序动作检测任务中,相邻帧的关系是任务的一个关键因素。然后,这一点却没有得到之前工作的重视。为此,该团队提出了一种基于数据增强加一致性约束的范式,显著地提升了弱监督的视频时序动作检测的性能。相关成果以“Unleashing the Potential of Adjacent Snippets for Weakly-supervised Temporal Action Localization”为题,将发表在国际会议ICME2023上。
弱监督的视频时序动作检测任务旨在在只有视频级的动作标签情况下,学习如何定位动作片段的时间区间和动作类别。相比较全监督的视频时序动作检测任务,弱监督的视频时序动作检测任务由于无需对视频帧进行精确标注等原因近年来收到学术界越来越多的关注。然而,该研究团队发现当前弱监督的视频时序动作检测方法在识别相邻帧的时候存在不足,导致无法准确的实现动作边界定位。该问题/动机的示意图如下所示:
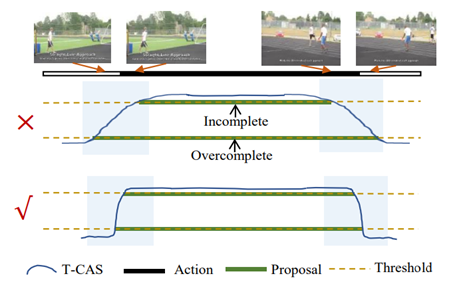
图1. 研究动机示意图
针对上述的研究动机,该研究团队提出一种基于数据增强&一致性约束的框架充分挖掘相邻帧在弱监督的视频时序动作检测任务中的潜能,从而实现对动作边界的准确定位。如图2所示,首先,我们将相邻两(母)帧的特征进行线性加权产生新的(子)帧。考虑到相邻帧的连续性,连续的两帧往往比较相似而且它们的时序位置应该处于两个相邻帧之间,因此我们可以认为新增的子帧序列重新构成一个连续的新的视频序列。然后,我们对这些新的视频序列进一步施加三种一致性约束:首先,我们约束子帧序列的视频级语义和母帧序列的视频级语义相同。这样我们可以用是视频级的标签去训练这些子帧序列,从而挖掘更多的区域。其次,我们约束每个子帧的预测和其母帧预测的线性插值一致,这样便可以使得帧级的预测在时序上更为平滑。最后,每个子帧特征与其母帧的特征按加权的比例靠近,与其他帧特征远离,通过学习这种细微的相似度,它能够让模型学习到帧的细节信息,从而方便更好地前景和背景的分离。我们提出的这个方法具有很强的简便性和通用性,理论上可以和任何其他弱监督的动作检测方法结合一起使用。

图2. 弱监督的视频时序动作检测方法框图
我校信息科学技术学院的博士研究生刘钦颖为本论文第一作者,王子磊副教授为论文通讯作者,博士研究生陈若曦和李志林分别为第三和第四作者。该工作得到了国家自然科学基金委的资助。
论文链接:待更新
代码链接:待更新