近日,中国科学技术大学信息科学技术学院的王子磊副教授在视频半监督学习方向取得了新进展。该研究团队受人类识别过程的启发,即利用视频数据内部的时间相关性,借助历史帧中的显著语义概念来帮助识别当前帧,提出了一种新颖的时间依赖分类器(TDC),以模拟人类识别过程。相关成果以“Infer from What You Have Seen Before: Temporally-dependent Classifier for Semi-supervised Video Segmentation”为题发表在计算机视觉顶级国际会议CVPR2024。
由于人工劳动成本高昂,语义分割在实际应用场景中的一个主要挑战是缺乏足够的像素级标注,这一问题在处理视频数据时尤为严重。为利用未标注数据进行模型训练,半监督学习方法尝试构建伪标签或各种辅助约束作为监督信号。然而,大多数方法只是将视频数据作为一组独立的图像逐帧处理,忽略了丰富的时间关系,而这些关系可以作为表示学习的宝贵线索。此外,这种逐帧识别的方式与人类的识别过程截然不同。事实上,人类会利用视频数据内部的时间相关性,明智地利用历史帧中的显著语义概念来帮助识别当前帧。
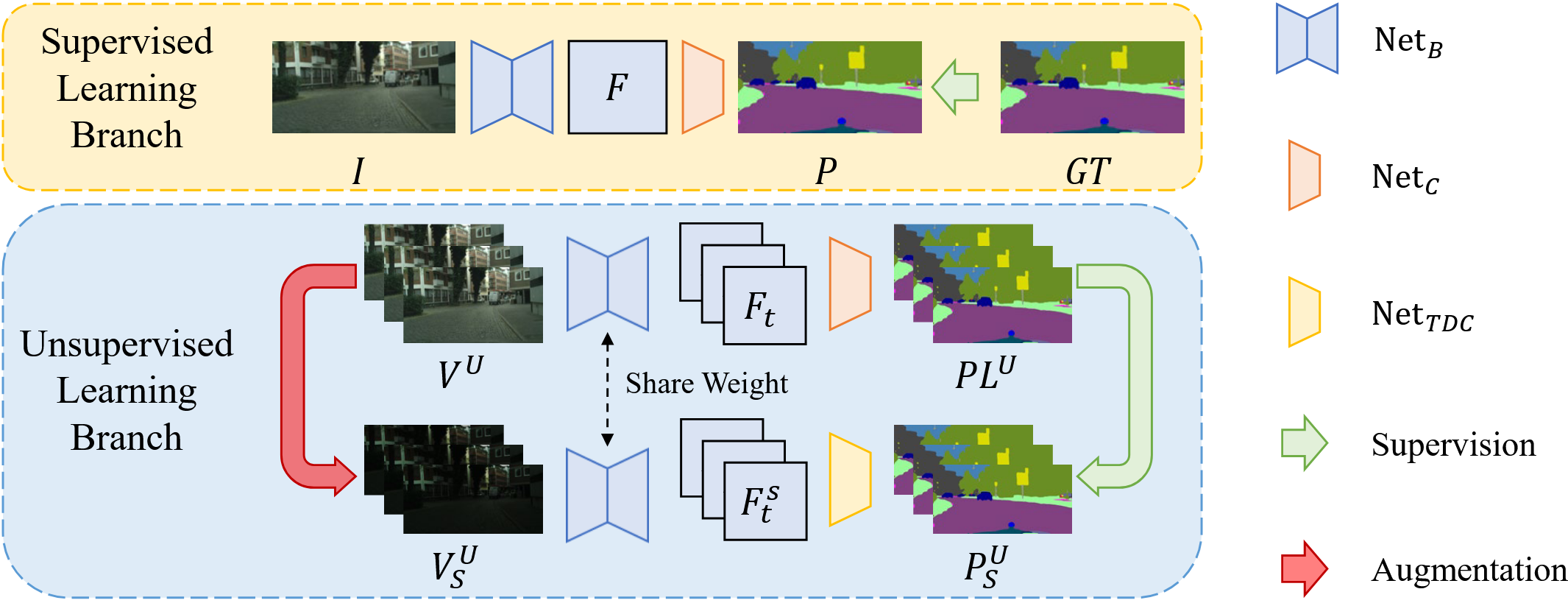
图1 模型结构图
受人类方式的启发,研究人员提出设计一种新颖的时间相关分类器(TDC),它更适合视频感知。具体而言,TDC 包含两种类型的原型,即全局原型和上下文原型。前者在模型训练期间学习全局语义概念,并在推理期间固定,这与传统分类器相同。不同之处在于,上下文原型是根据最后处理的帧动态计算的。在识别当前帧时,两种类型的原型协作在一起以计算与提取的特征的相似性。通过这种方式,从历史帧中区分出的上下文概念可以帮助分类。
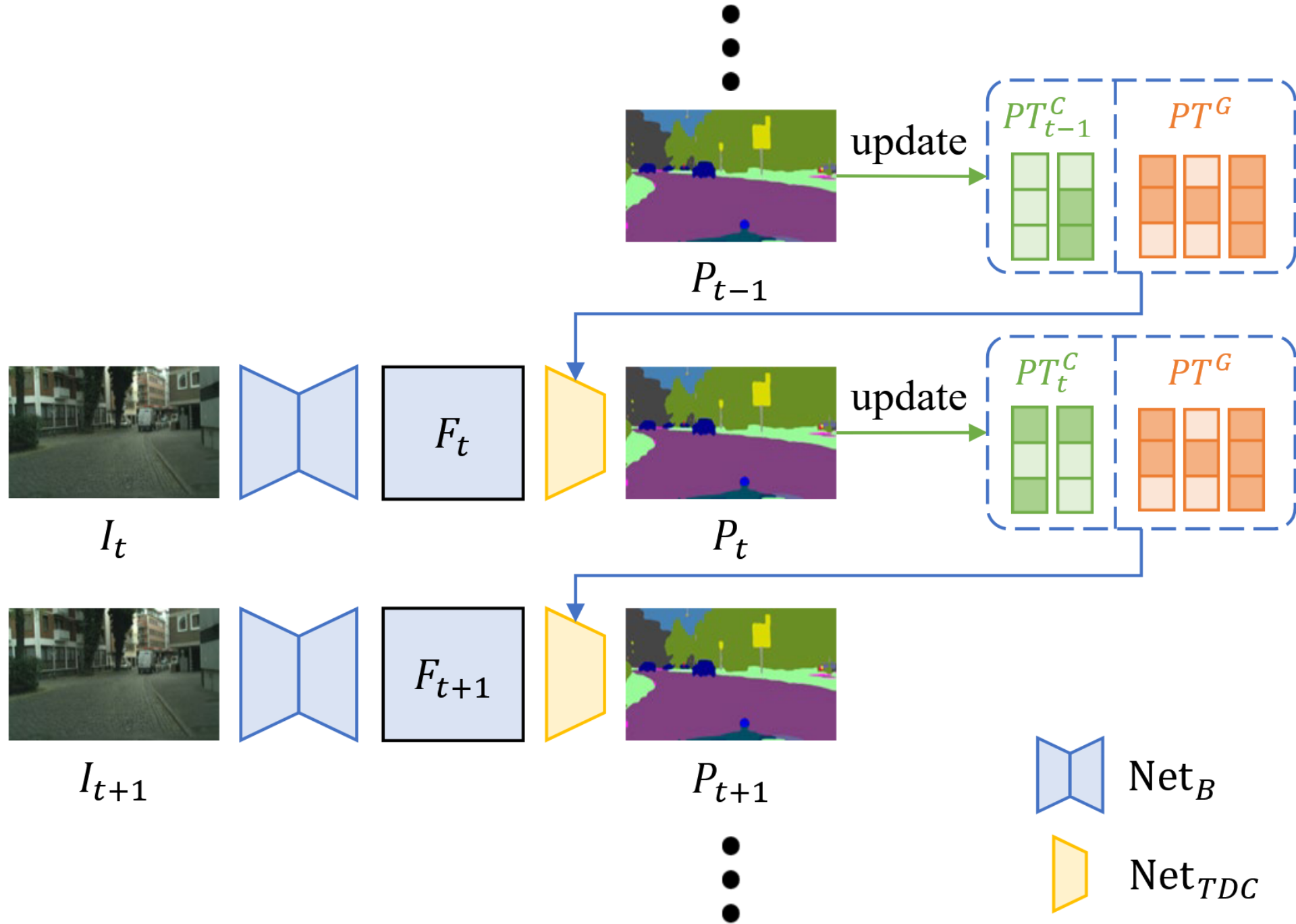
图2 时序依赖的识别过程示意图
从实验结果中,研究人员发现,通过在半监督视频分割任务中配备简单的伪标签监督,TDC 可以实现显着的性能提升。主要原因是时间相关识别范式隐式地施加了时间一致性约束。具体而言,TDC 实际上需要从历史帧计算出的上下文原型来准确表示当前帧的内容。这样,特征提取器就会被引导去学习一组跨帧时间一致的语义概念,从而间接地将内容相关性先验引入到特征提取过程中。这种引导有效地优化了无标记数据上的模型训练,提高了泛化能力。
中国科学科学技术大学自动化系博士庄嘉帆为该论文第一作者,中国科学技术大学信息科学技术学院王子磊副教授为该论文的通讯作者。该研究得到了国家自然科学基金的支持。
论文地址:CVPR2024
代码地址:待更新