近期,中国科大视觉与多媒体研究组与中科院自动化所谭铁牛院士课题组在黑盒视觉语言模型微调方向取得新进展。视觉语言模型微调(Fine-tuning for Vision-Language Models)是计算机视觉研究中的一项重要任务。然而,现有的微调方法通常需要访问模型参数,这在模型所有者倾向于将模型作为黑盒提供以保护所有权的情况下具有挑战性。研究组提出了一种针对黑盒VLMs的协作式微调方法(CraFT),该方法只需要访问模型的输入提示和输出预测。相关成果以“Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models”为题发表在ICML 2024。
近年来,大规模预训练视觉语言模型引起了广泛关注。通过在图像和自然语言之间建立联系,这些模型表现出令人印象深刻的零样本能力和卓越的迁移能力,展示了学习开放世界概念的潜力。最成功的大规模预训练视觉语言模型之一是 CLIP。预训练后,CLIP只需提供类名称即可执行零样本识别。分类权重由语言编码器通过提示生成。除了其卓越的零样本能力外,最近的研究发现CLIP还具有惊人的迁移能力。例如,与 Zeroshot CLIP相比,CoOp可以通过微调 16k 个参数,每类仅 16 个样本,实现 15% 的改进。然而,这些方法假设我们可以访问模型参数,这在当今时代是不现实的。训练大型视觉语言模型通常需要大量的计算资源和数据,从而导致高昂的训练成本。因此,模型所有者很少发布模型和权重,以保护模型所有权。通常,模型所有者将模型部署为服务,例如 GPT4,我们只能获取输入和输出。因此,探索在黑盒场景中微调强大的视觉语言模型的方法至关重要。
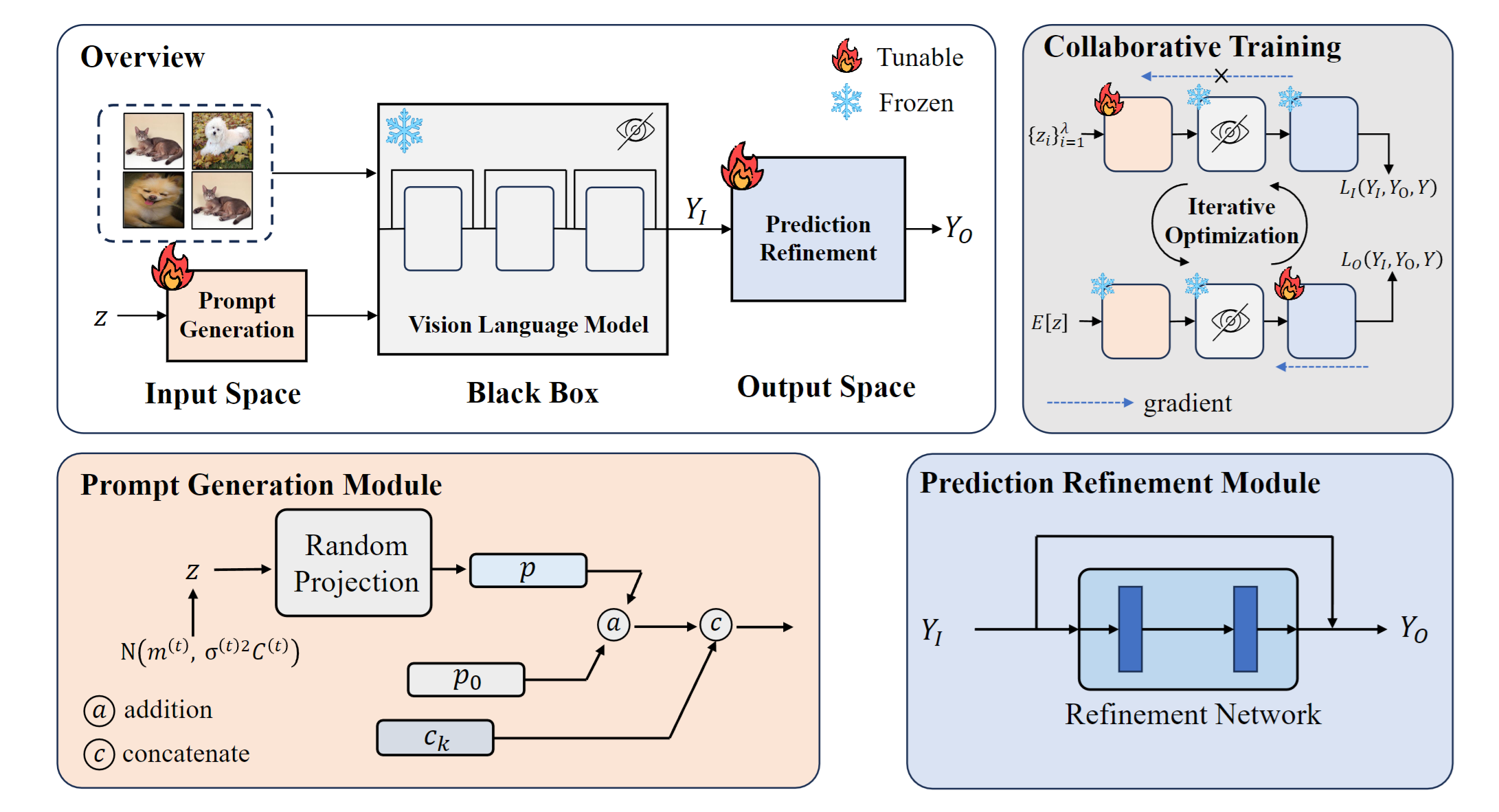
图1 方法示意图
为解决黑盒微调的挑战,该工作在输入和输出空间分别集成了可学习模块。在输入空间,提示生成模块使用CMA-ES算法学习下游任务的全局文本提示。在输出空间,预测细化模块以残差形式细化黑盒模型的输出预测。由于两个模块使用不同的优化器,该工作提出了一种协作训练算法来联合训练它们。具体而言,通过将带有残差连接的模型重新表述为每层输出的加法,使得可以交替优化这些模块。在15个数据集上的少样本分类实验表明,CraFT显著优于黑盒基线方法。与白盒方法相比,CraFT训练更快,部署时只需要1/80的内存占用。该工作为黑盒VLMs的微调提供了一个新的框架,为进一步探索这一方向奠定了基础。
中国科学技术大学博士生王政博为本文第一作者,中科院自动化所梁坚研究员为论文通讯作者。该工作得到了国家自然科学基金委的资助。