近日,中国科学技术大学信息科学技术学院的王子磊副教授在域适应学习方向取得了新进展。该研究团队指出在域适应图像分类任务中需要解决特征偏离类别权重的问题,以提高特征跨分布的迁移性,而当前普遍使用的特征对比学习无法解决该问题。研究组为此提出了基于概率对比学习的域适应方法,在多个域适应任务下均有明显的性能提升。相关成果以“Probabilistic Contrastive Learning for Domain Adaptation”为题发表在人工智能顶级国际会议IJCAI 2024。
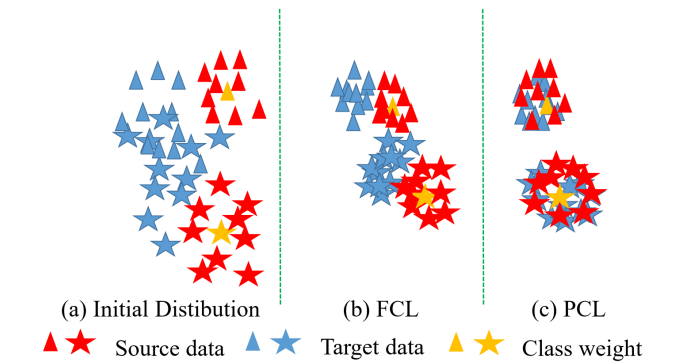
图1.域适应任务的特征分布与对比学习概况
在域适应问题中,源域数据的分布和目标域数据的分布存在明显的差异,这种差异叫做领域漂移。由于领域漂移问题的存在,如果将源域训练的模型直接应用在目标场景中,将导致模型性能急剧下降。对于一个分类任务,为了获得良好的性能,应该保证特征本身具有可区分性,即语义相同的特征应尽可能紧凑,语义不同的特征应该互相远离。然而,在域适应任务中,由于目标域数据缺乏可进行有监督学习的类别标签,因此从目标域数据中提取的特征通常比较分散且无法区分。大量的研究工作表明,特征对比学习可以在无标注数据上学习语义紧凑的特征表示,即倾向于将语义相似的特征聚集在一起,提高目标域特征的可区分性,但仍无法保证特征靠近其对应的类别权重,因此还是难以正确进行分类。
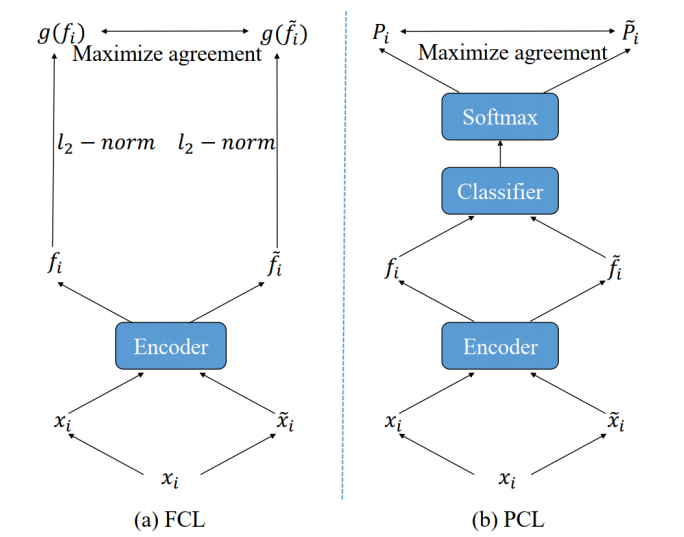
图2. 特征对比学习(左)与概率对比学习(右)的差异
针对上述问题,研究人员深入分析了传统特征对比学习在域适应问题表现不佳的原因,并设计了一个简单且即插即用的概率对比损失。具体而言,在分类任务中,特征需要接近其对应的类别权重。研究人员指出,特征对比学习使用分类器之前的特征计算对比损失,此过程不涉及类别权重的信息,因此它无法约束特征聚集在类别权重周围。基于上述分析,研究人员设计了一个简单且即插即用的概率对比损失,它使用概率替换传统特征对比学习中的特征,并移除L2归一化。在概率对比损失优化的过程中,对于目标域类别的分类概率将趋近于one-hot形式,从而引导概率分布在目标域中围绕相应的类别权重进行聚类。在多个不同的域适应任务以及多个基线模型下的实验表明,概率对比方法方法可以明显地提升基线模型的性能并且超过了很多设计复杂的方法。
中国科学科学技术大学自动化系博士李俊杰为该论文第一作者,中国科学技术大学信息科学技术学院王子磊副教授为该论文的通讯作者。该研究得到了国家自然科学基金、安徽省重点研发计划的支持。
论文地址:https://arxiv.org/abs/2111.06021
代码地址:https://github.com/ljjcoder/ProbabilisticContrastive-Learning