近日,中国科学技术大学视觉与多媒体研究组在多模态大模型的视觉信息交互机制研究方面取得重要进展。研究团队发现,尽管图像标记在模型输入中占据较大比例,但其对最终预测结果的影响微乎其微,仅相当于指令标记的 0.03%。基于这一发现,研究团队深入解析了 MLLMs 处理视觉信息的模式,并提出了一种加速推理的方法—分层模态感知剪枝(Hierarchical Modality-Aware Pruning, HiMAP),在减少计算开销的同时保持模型性能。相关研究成果以“Hierarchical Modality-Aware Pruning: Accelerating MLLMs via Structured Visual Token Pruning”为题,已被国际会议 CVPR 2025 录用。
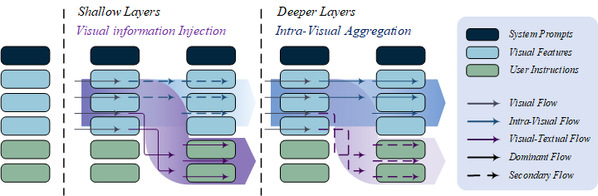
图-1 多模态大模型对视觉信息的阶段性处理模式
近年来,多模态大模型在计算机视觉和自然语言处理任务上展现出卓越性能。相比传统多模态模型,MLLMs 依托大语言模型处理视觉特征,实现更深入的信息融合。然而,MLLMs 内部的视觉信息交互机制仍缺乏系统性研究。为解答图像标记对预测的影响及其在模型内部的流动方式,研究团队设计了一系列基于显著性分析的实验,揭示了 MLLMs 在不同深度层对视觉信息的不同处理模式。研究发现,在模型的浅层,图像标记主要与指令标记交互,将视觉信息注入文本模态,以建立跨模态的语义表示;而在深层,图像标记之间的交互增强,用于整合残留的视觉信息,进一步优化视觉模态的语义表征。这一分阶段的信息处理机制解释了为何图像标记在最终预测中的贡献较小,并为优化 MLLMs 的计算开销提供了理论依据。
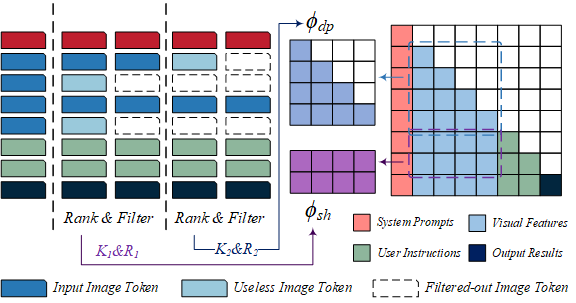
图-2 分层模态感知剪枝算法示意图
尽管图像标记的计算量庞大,其对模型预测的贡献却极其有限,这导致 MLLMs 在推理过程中存在较大的计算冗余。为此,研究团队提出 HiMAP 方法,通过动态评估图像标记的重要性,在不同深度层进行结构化剪枝,从而减少计算负担。HiMAP 结合显著性分析,依据不同层级的视觉信息流,合理裁剪影响较小的图像标记,并优化自注意力和前馈网络的计算流程。实验结果表明,HiMAP 在减少 65% 以上计算量的同时,仅对模型性能造成极小影响。具体而言,HiMAP 将 MLLMs 的推理延迟降低约 50%,在保持模型性能的同时大幅提升推理效率,为多模态模型的实际应用提供了更高效的解决方案。
我校人工智能与数据科学学院硕士生殷皓为该论文第一作者,王子磊副教授为论文通讯作者。