近日,中国科学技术大学视觉与多媒体研究组在多模态大模型的目标幻觉问题上取得突破。研究团队发现,现有的对比解码方法虽然能够减少模型对语言先验的过度依赖,但往往会降低生成文本的连贯性和准确性,同时显著增加推理时间。针对这一问题,该团队提出了一种无训练的方法—视觉增强融合(Visual Amplification Fusion, VAF),在不影响推理速度的情况下,有效提升模型的视觉表征能力,显著缓解目标幻觉问题。相关研究成果以“ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large Language Models”为题,已被国际会议 CVPR 2025 录用。
目前,视觉对比解码(Visual Contrastive Decoding, VCD)方法被广泛用于缓解目标幻觉,其核心思想是通过对比原始视觉输入与扰动后视觉输入的输出分布,减少模型对语言先验的依赖。然而,该方法存在两个主要问题。首先,在降低目标幻觉的同时,VCD 可能会削弱生成文本的连贯性和准确性,导致输出质量下降。其次,VCD 需要分别处理原始输入和对比输入,计算量增加一倍,导致推理速度大幅下降,影响实际应用。
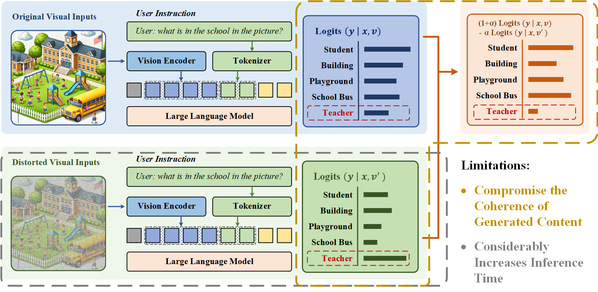
图-1 VCD方法存在缺陷示意图
针对这一问题,研究团队深入分析了多模态大模型的模态融合机制,发现目标幻觉的根本原因并非模型对语言信号的过度关注,而是视觉信息在模态融合过程中未能得到充分利用。基于这一发现,该团队提出了一种即插即用的方法—视觉增强融合(VAF)。该方法在不改变模型架构的情况下,通过在中间层增强视觉信号,使模型在模态融合阶段捕获更清晰的视觉特征,从而减少生成文本中的错误描述。与 VCD 方法相比,VAF 具有显著优势。VCD 通过削弱语言先验来减少目标幻觉,容易影响内容质量,而 VAF 则在增强视觉信息的同时保留了语言先验的积极作用,确保生成内容的连贯性和准确性。此外,VCD 需要额外处理对比样本,推理时间增加 50%,而 VAF 直接作用于模型的模态融合阶段,不增加额外计算开销,推理速度基本不受影响。
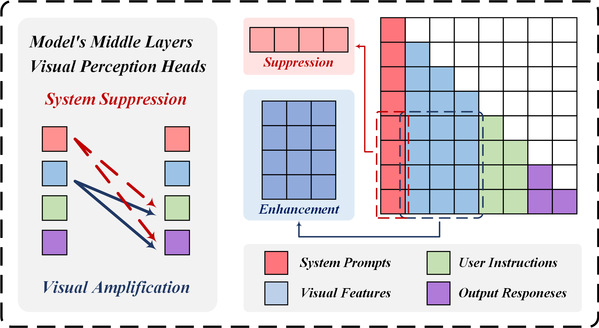
图-2 视觉增强融合方法示意图
实验结果表明,VAF 方法在多个目标幻觉基准测试中均取得了显著性能提升。在 POPE 和 MME 数据集上,VAF 分别提升了 3% 和 7% 的目标幻觉缓解能力。在 NoCaps 数据集上,VCD 方法会导致内容质量下降 19%,而 VAF 在保持高质量生成内容的同时减少了目标幻觉。此外,VCD 会导致推理速度下降 50%,而 VAF 几乎不会影响推理速度。这些实验结果充分验证了 VAF 方法的有效性和实用性。
我校人工智能与数据科学学院硕士生殷皓为该论文第一作者,王子磊副教授为论文通讯作者。