近日,中国科学技术大学信息科学技术学院的王子磊副教授在半监督视频语义分割方向取得新进展。该研究团队发现了视频语义分割中的帧间过拟合问题,并针对性提出了帧间特征重构方法以拉近视频片段不同帧的特征分布,有效地解决了帧间过拟合问题,显著地提高了半监督视频语义分割的质量。该研究为半监督视频语义分割领域提供了新思路。相关成果以“Semi-Supervised Video Semantic Segmentation with Inter-Frame Feature Reconstruction”为题发表在计算机视觉顶级国际会议CVPR 2022。
半监督视频语义分割旨在利用少部分标注数据和大量无标注数据进行模型训练。其中,每段视频数据为30帧,仅有少量视频片段的第20帧有标注。现有方法仅仅使用了每段视频的第20帧数据进行半监督学习,而忽略了第20帧外的大量无标注视频帧数据。

为了充分利用所有视频数据,本工作将剩余视频数据视为额外的无标注数据参与训练,并发现了帧间过拟合问题。模型对同一视频中不同帧的预测质量存在差异——模型在标注帧20的预测结果很好,其余无标注帧15、10、5的预测结果较差。这是由标注帧和无标注帧的监督信号不同。

为了解决帧间过拟合问题,研究者们考虑了视频数据的内在相关性,通过单帧的标注为无标注帧提供准确的监督信号。为此,研究者们设计了帧间特征重构方法。首先,利用无标注帧的特征计算类别原型。接着利用类别原型对标注帧特征进行特征重构,然后利用标注信息进行语义监督。通过这种方式,无标注帧的监督信号与有标注帧的监督信号质量相同,从而解决了帧间过拟合问题。此外,帧间特征重构方案还可以方便地扩展到无标注视频片段和强增强数据上,以获得更高的语义分割质量。
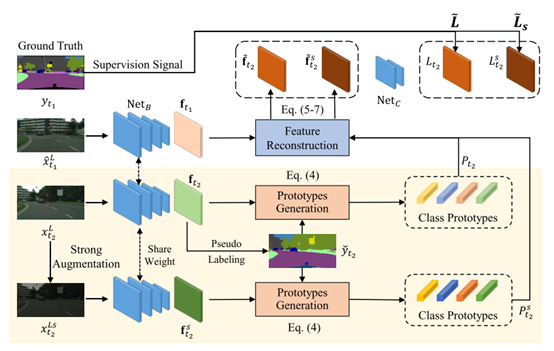
该研究针对现有视频语义分割方法在训练过程中无法充分利用无标注视频数据的问题,提出了一种基于特征重构的半监督学习方法。利用视频数据的内在相关性,通过无标注帧特征对有标注帧进行重构表征,从而有效利用仅有的一帧标注对无标注帧提供准确语义监督,解决了帧间过拟合问题。
中国科学技术大学王子磊副教授为该论文的通讯作者;信息科学技术学院的博士生庄嘉帆为该论文的第一作者,博士生高源为该论文的第三作者。