近日,VIM研究组在图像分类任务的无源域适应学习方向取得了新进展。团队探索了语义类别关系这一跨域鲁棒的知识,并提出了类别关系嵌入的样本相似度和对比损失,这项研究为无源域适应领域提供了新思路。相关成果以“Class Relationship Embedded Learning for Source-Free Unsupervised Domain Adaptation”为题发表于计算机视觉顶级国际会议CVPR2023。
传统的有源无监督域适应学习方法通过将知识从标签丰富的源域转移到标签稀缺的目标域,来缓解目标域对于标注的依赖。但是在一些涉及隐私的真实场景(例如医学图像、监控视频),通常无法访问源域数据,而只能获取源域模型,为此提出了无源无监督域适应问题,即只给定源域模型的情况下,如何在无标注的目标域上实现知识的迁移,其中核心问题是寻找跨域可迁移知识。已有的一些方法假设源域假设(Source Hypothesis),包括分类器或整个模型,包含足够知识用于目标域训练,为此,通过使用固定源分类器 直接对齐特征、借助历史模型生成对比损失的正样本以及权重正则化 等手段来传输源知识。另外一些工作假设源域模型已经形成了某种语义结构,然后利用特征空间的局部信息(即邻域)来加强输出空间中的相似性。尽管取得了有效的进展,但哪些知识可以迁移仍然是一个有待解决的问题。
为了探索源域模型中的领域不变知识,VIM研究组指出语义类别关系具有跨域一致性,并提出了类别关系嵌入的学习过程,其原理如图1所示。具体地,类别关系利用分类器权重计算得到的类别相似性矩阵进行建模,然后提出了一种新的基于概率空间的样本相似度计算方法,包括类内相似度和类间相似度,其中类间相似度使用类别相似性矩阵作为系数。相比于基于特征的样本相似度,可以有效地优化分类器参数;相比于只使用类内相似度,可以更加准确地表达样本在特征空间的实际位置关系。
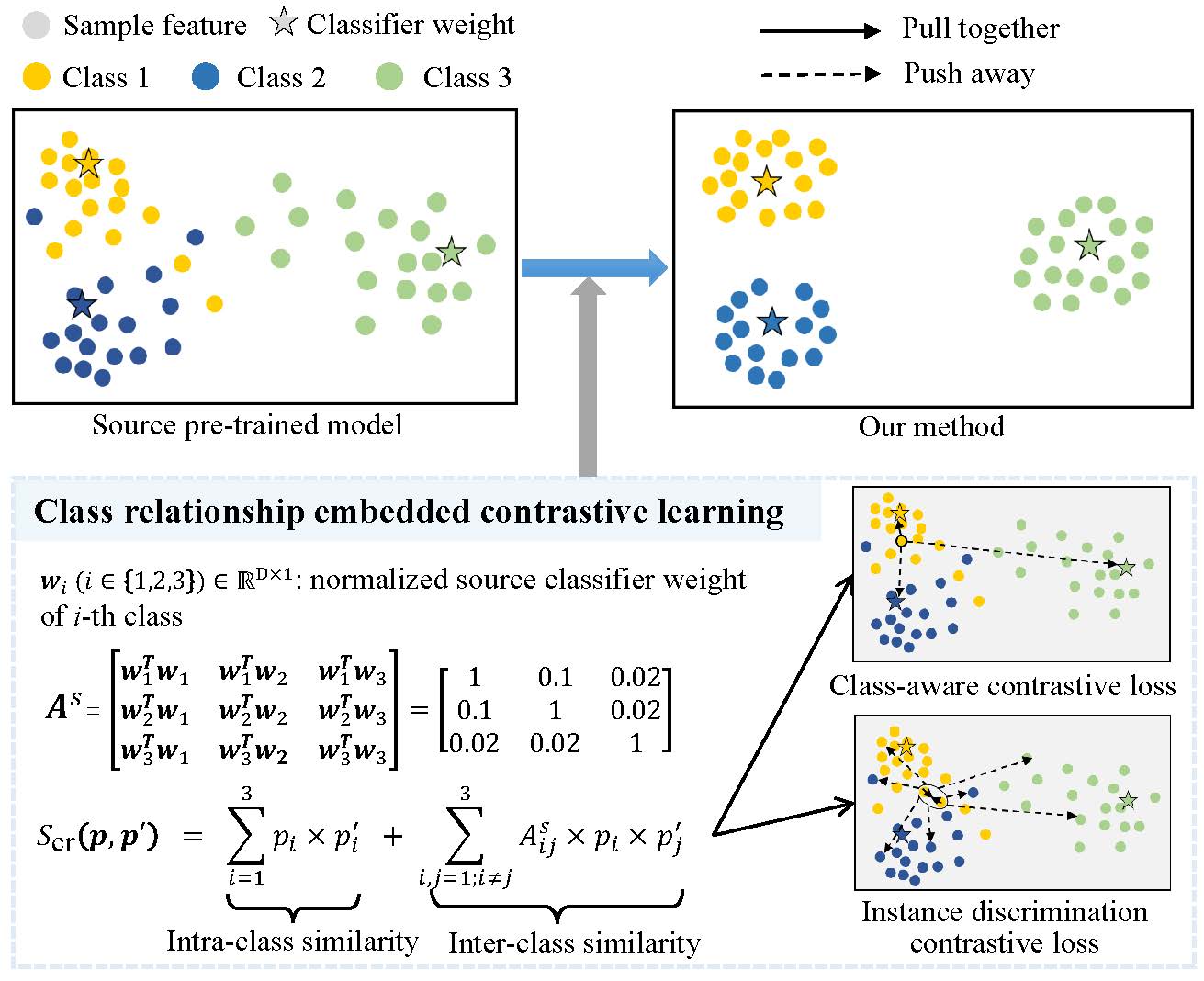
图 1 类别关系嵌入的相似度计算和对比学习原理示意图
基于样本相似度矩阵,VIM研究组进一步提出了两种对比损失形式用于目标域样本的学习,模型结构如图2所示。一种是类别感知的对比学习,其正样本是由伪标签对应的One-hoe形式概率,负样本是其他类别的概率;另一种是实例区分的对比损失,正样本是同一个样本的不同强增的概率,负样本是其他样本的概率。前者是在目标域高置信样本上计算,可以后者是在所有目标域样本上训练。通过引入类别关系,可以减小噪声伪标签的负面影响,提升目标域特征的判别性。VIM研究组在单源域无监督域适应、多源域无监督域适应、开放集域适应和部分集域适应任务上验证了该方法的有效性,在多个数据集中去得到了当前最好的性能。
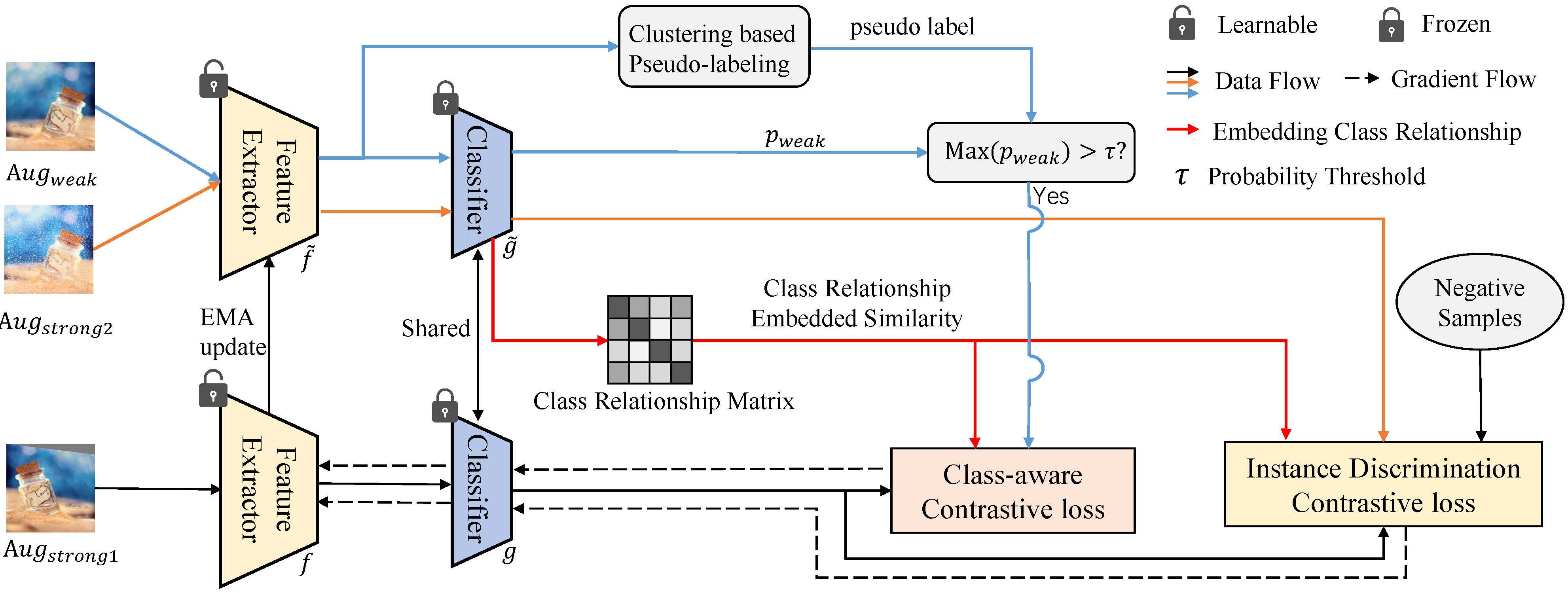
图 2 类别关系嵌入的类别感知对比学习和实例区分对比学习框架图
我校信息科学技术学院的博士后张燚鑫为本论文第一作者,王子磊副教授为论文通讯作者,贺伟男为第三作者,在方案讨论、代码实现和实验运行方面提供了有力支持。该工作得到了国家自然科学基金委、安徽省科技厅和中国科学技术大学创新团队培育基金的资助。
论文链接:CVPR2023-CRCo