近日,VIM实验室在持续学习语义分割方向取得新进展。通过对特征空间中的信息进行结构化建模与保持,配合将特征图映射至一独立的嵌入空间中加以对齐的方式,提出了一种能有效平衡旧知识保持和新知识学习的持续学习语义分割技术框架。相关研究成果以“Continual Semantic Segmentation via Structure Preserving and Projected Feature Alignment”为题发表于2022年的欧洲计算机视觉会议(ECCV2022)上。
当前对语义分割网络的训练需要一次性获取所有训练数据,以离线的方式进行训练。在现实的实际应用场景中,常会遇到数据逐渐增加的场景。简单的在这些数据上微调网络会导致其仅拟合这些新数据而遗忘已学会的知识,即灾难性遗忘现象。为此,提出了增量学习方法。特别地,本工作关注类别增量学习,其目的是使语义分割网络在无法重新使用过往数据与类别标注的情况下,在新增数据上持续的学习新类别并且保留对已学习类别的分割能力。
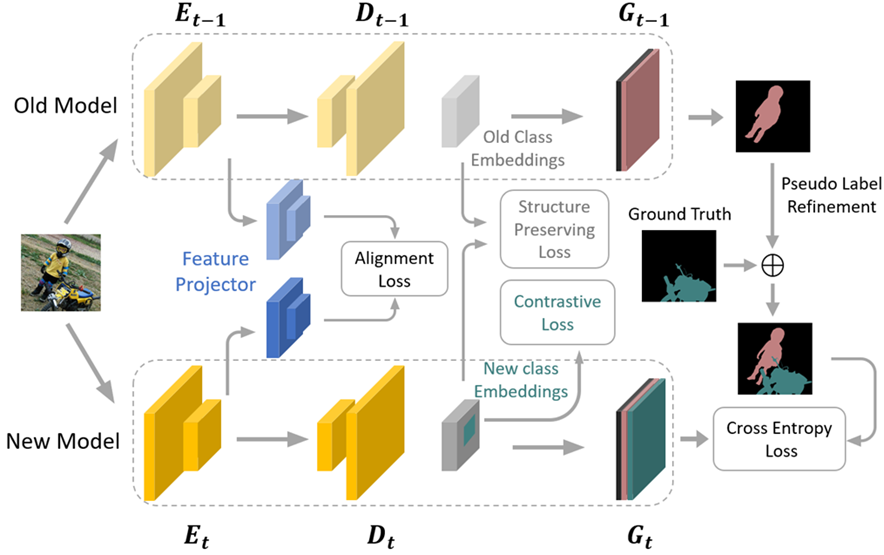
图 1 方法结构图
在增量学习中,几乎所有的工作都应用了知识蒸馏技术以防止旧知识的遗忘问题。当前大部分类别增量语义分割工作主要将图像分类领域中的技术直接应用在语义分割任务中。这导致了两个问题:其一,在类别增量语义分割任务中,我们将当前不感兴趣的语义类别标注为背景。但是在未来的学习阶段,我们很可能需要学习这些曾经忽略的类别。因此对于一给定图像,其所包含的语义是变化的,这就是类别增量语义分割不同于图像分类任务的最大区别。这一现状导致了对于固定的输入,其在特征空间中的表示需要不断的被更新。现有工作沿用了分类任务中的知识蒸馏技术,对旧类别惩罚嵌入表示的任何变化,因此可能造成优化冲突,从而降低性能。其二,当前主流的基于CNN的语义分割网络都可以抽象为编码器—解码器结构。其编码器常使用图像分类任务中的网络(例如ResNet)。现有工作参考了图像分类任务中的实践,仅考虑了编码器的遗忘现象,忽略了解码器部分。我们指出解码器上同样存在着明显的遗忘现象,并且克服这一因素后会带来明显的性能增益。为此,我们在考虑了类别增量语义分割任务语义变化需求的基础上,针对编码器和解码器分别针对性设计蒸馏损失,从而有效平衡旧知识的保留和新知识的学习。
对于解码器,直接对齐新旧网络的输出会导致优化冲突。因此首先使用旧网络提取的特征图训练一自编码器,利用其生成关于旧知识的低维嵌入表示。对于新网络同样使用此操作并对齐二者生成的低维嵌入表示。由于自编码器的性质保证其提取的低维嵌入表示包含重建原始特征图的信息,因此,对新网络而言,无论其输出的特征图如何变化,只要能生成与旧网络相同的低维嵌入表示,则说明其仍然保有完整的旧知识。对于解码器,我们同样不直接对齐新旧网络二者的输出以避免前述优化冲突问题。由于解码器的输出更加靠近实际语义类别,因此我们通过其输出在类间拓扑关系和类内拓扑关系上对旧类别的知识进行建模。并在学习过程中对齐新、旧网络的上述关系,避免直接对齐旧类特征与新类学习间的矛盾,同时能有效的保留旧类别的判别力。同时对于新增类别,我们使用对比损失优化新类在特征空间中的结构,以获取类内紧凑、类间边界清晰的结构,使其更难发生遗忘现象最后,使用旧网络的预测结果作为伪标签,以标记标签中缺失的旧类别。