近日,中国科大视觉与多媒体研究组与中科院自动化所谭铁牛院士课题组合作,针对目前制约联邦学习发展的节点数据非独立同分布问题中较为复杂的属性倾斜因素,提出了基于互信息约束的解耦联邦学习框架。相关成果以“Disentangled Federated Learning for Tackling Attributes Skew via InvariantAggregation and Diversity Transferring”为题发表于机器学习顶级国际会议ICML 2023。

图一:MNIST数据集颜色属性偏差造成的性能损失
在实际场景中,由于数据采集场景、设备、对象的差异性,属性倾斜是普遍存在的且严重阻碍了联邦学习的进一步发展与实际应用,数据分布异质性会之所以会导致优化偏差的本质原因在于:特定节点数据的特有属性不可避免地被节点模型提取并混合到全局聚合中。这些属性能被成功学习说明其与决策相关,但可惜不是因果关系,也仅在局部有效。举个鸟类分类的例子,数据集为飞鸟的节点网络通过本地模型同时抽取到鸟本身和蓝天的属性,这两者都有助于飞鸟数据的分类决策。不幸的是,蓝天作为飞行鸟类图片所特有的属性会通过模型聚合注入到全局模型中。对于数据集中鸟都在树上的节点而言,对于蓝天属性的关注会导致分类性能下降,因为这个数据域没有蓝天这一概念。而实际中这种属性倾斜的现象非常普遍,进而引发了人们对联邦学习系统的鲁棒性和可信赖性的担忧。
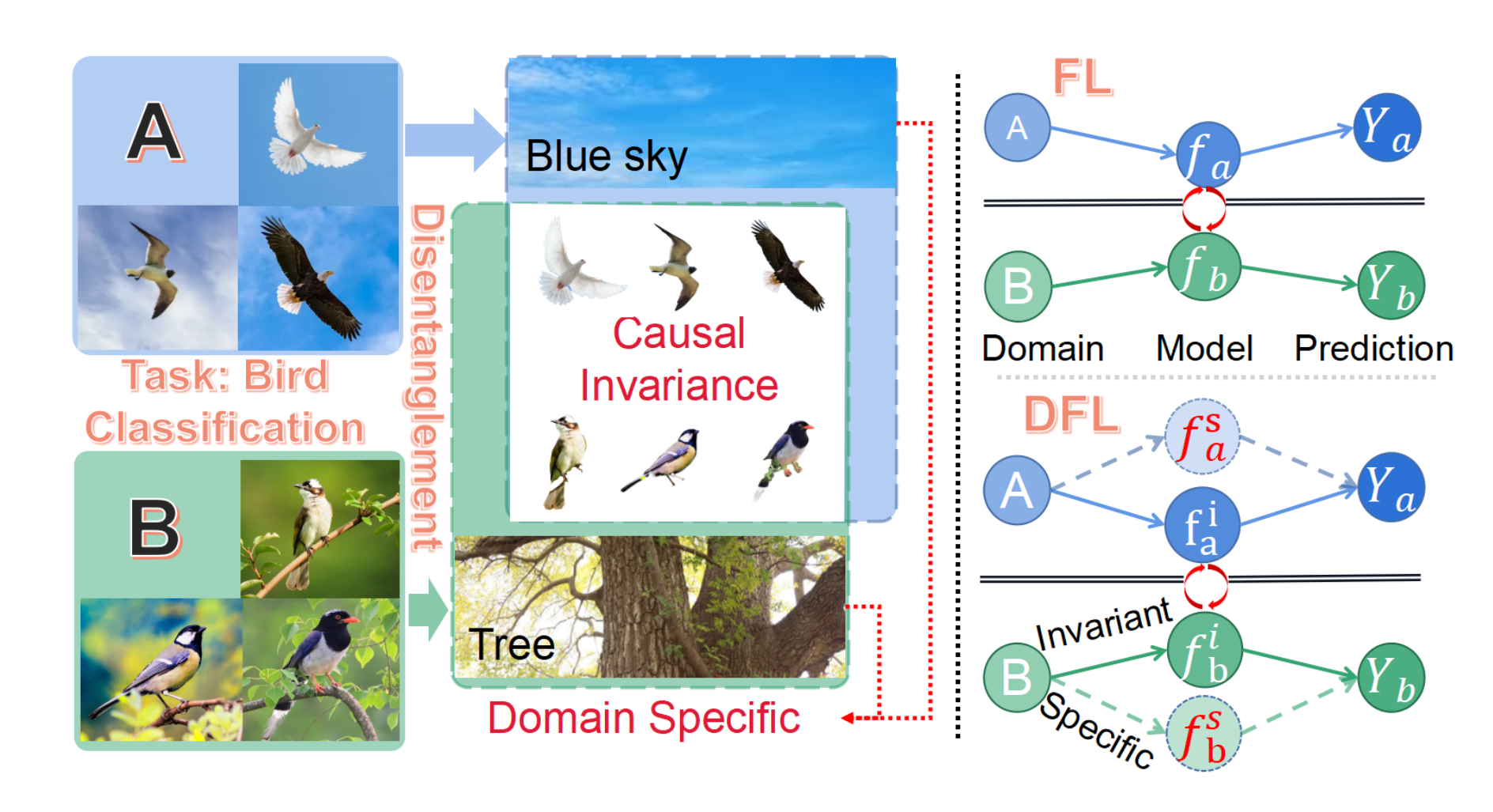
图二:鸟类分类实例和DFL原理
根据以上的观察提出了解耦联邦学习,其动机就是要从聚合模型中剥离节点特有的属性。但是,传统联邦学习框架通常基于单分支模型无法支撑DFL,其主要原因在于单分支模型会同时提取到高度纠缠的特有和不变属性。虽然这两个属性都有助于局部的任务决策,但其差异在于1)不变属性是内在的和因果的,是跨域通用的; 2) 特定属性仅在本地有效,可能会给其他域带来性能下降。因此,解耦联邦学习首度采用了两个互补分支的节点模型,引入互信息约束解开纠缠的属性,并分别汇聚到不同的分支上:1)特定领域的分支只在本地训练。 2) 域不变分支应用于全局聚合。除了重新设计局部节点模型外,为了有效实现解耦联邦学习架构,本工作提出了不变聚合和多样性转移两种新技术。
本文通讯作者为谭铁牛院士,合作者还包括骆正权博士、王云龙副研究员、和孙哲南研究员。该项目得到国家自然科学基金委等项目的支持和CAAI-Huawei Mindspore 开放基金赞助。