近日,VIM研究组在图像目标检测任务的无源域适应学习方向取得了新进展。团队发现,以往的工作往往都会采用基于伪标签的方式进行自训练,但它们只适合利用高置信度的伪标签,而忽略了一些有价值的低置信度伪标签。为此,该团队提出了一种处理伪标签的新范式,将高置信度和低置信度伪标签都高效利用起来。相关成果以“Exploiting Low-confidence Pseudo-labels for Source-free Object Detection”为题发表于多媒体顶级国际会议ACM MM2023。
由于在目标域上缺乏人工标注的数据,大多数现有的无源域适应目标检测的方法都采用mean-teacher的架构进行训练。该算法将模型分为teacher和student,teacher模型负责生成student模型学习的目标。这一过程采用的是基于阈值的伪标签方法。只有置信度高于阈值的伪标签会被引入到训练中。现有的方法通常手动设置一个很高的阈值,以确保高质量的伪标签。此外,由于类别不平衡的数据分布,不同类别的最佳阈值往往不同。因此传统的设置会导致很多有效的伪标签信息被丢弃,影响了模型的性能。
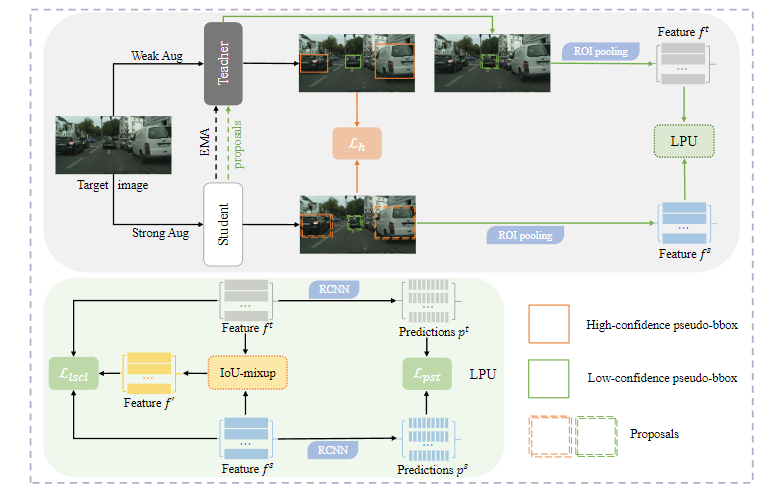
图1 模型结构图
针对上述问题,该论文提出了一个新的处理伪标签的模块(Low-confidence Pseudo-labels Utilization,LPU)。如图1所示,该文会设置一个高阈值和一个低阈值,对于置信度大于高阈值的的数据的伪标签,由于这部分伪标签的质量足够高,因此作者们采用常规方式直接进行训练。而对于置信度位于低阈值与高阈值之间的数据的伪标签,文章采用LPU模块进行训练。模块包含两个部分,一个是PST(Proposal Soft training),另一个是LSCL(Local Spatial Contrastive Learning)。PST旨在为proposal分配更准确的标签。具体来说,把student产生的proposals输入到teacher中,提取特征,将经过ROI head之后生成的分类分数作为soft label,然后进行自训练。另一方面,为了增强模型对空间位置邻近的proposal的判别能力,让模型能更精准的识别proposal的类别,不被错误的伪标签信息误导,作者们引入了LSCL模块。在这个模块,将空间位置邻近的proposal进行IoU-mixup,然后通过一致性对比学习损失进行优化。通过这种方式,鼓励模型在相邻的proposal之间探索更细粒度的线索,最终形成更鲁棒的分类边界。作者们在无源域适应目标检测任务上验证了方法的有效性,在多个数据集中取得了当前最好的性能。
中国科学技术大学大数据学院的硕士研究生陈志鸿为本论文第一作者,王子磊副教授为论文通讯作者,博士后张燚鑫为第三作者。该工作得到了国家自然科学基金等的资助。
论文链接:ACM MM2023
代码链接:待更新