近日,VIM实验室在持续学习语义分割方向取得新进展。通过在特征空间中使用对比学习对新增类别的类别知识进行挖掘,显著降低语义分割网络在后续学习阶段特征空间的优化难度,进而提升其对新类别的学习性能。相关研究成果以 “Preparing the Future for Continual Semantic Segmentation” 为题发表于2023年的国际计算机视觉会议ICCV2023上。
当前对语义分割网络的训练需要一次性获取所有训练数据,以离线的方式进行训练。在现实的实际应用场景中,常会遇到数据逐渐增加的场景。简单的在这些数据上微调网络会导致其仅拟合这些新数据而遗忘已学会的知识,即灾难性遗忘现象。为此,提出了增量学习方法。特别地,本工作关注类别增量学习,其目的是使语义分割网络在无法重新使用过往数据与类别标注的情况下,在新增数据上持续的学习新类别并且保留对已学习类别的分割能力。在本领域中,几乎所有的工作均关注于如何在新知识的学习与旧知识的保留中取得平衡。但在实际实践中,难以寻找到能有效同时兼顾二者的方法。此外,在新知识的学习阶段中,代表旧知识的样本数量很少,这将导致网络模型难以学习到具有较高判别力的特征从而良好地对新、旧类别进行判别。
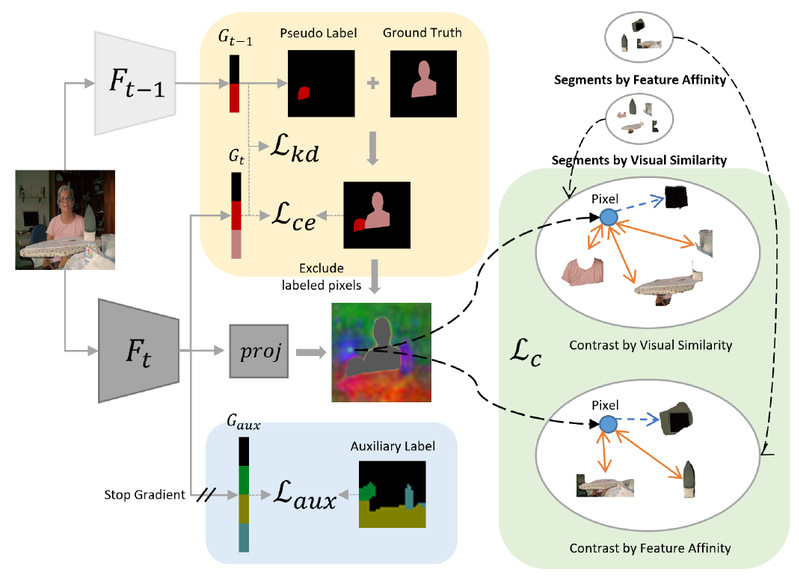
为此,我们针对这两个问题,提出了一种全新的训练流程以有效地解决它们。我们需要在当前的学习阶段中,利用持续学习语义分割问题训练数据中天然地包含没有学习过的类别(未来类)这一特性,在网络模型的学习更新过程中,显式地利用这些存在于训练数据中但是从未被标记过的未来类对网络进行优化。这一优化进一步分为特征空间优化与输出空间优化,以在不同的层面上有效引入网络模型对未来类别的先验知识,显著降低语义分割网络在后续学习阶段的优化难度,进而提升其对新类别的学习性能。具体地,在特征空间中,我们在这些未标记的类别上使用无监督对比学习对网络模型的特征进行优化;在输出空间中,我们应用聚类生成关于这些未标记类别的伪标签并训练以辅助分类器用于初始化后续阶段训练的分类器。相比于现有方法均关注于设计不同的知识蒸馏损失,配合训练过程的参数调整以在新知识和旧知识中取得较好平衡的目标,我们的方法则从全新的角度为提升持续学习语义分割问题的性能表现提供了新的研究思路和解决方案。
 、
、
图1 方法结构图
我校信息科学技术学院的博士生林子涵为本论文第一作者,王子磊副教授为论文通讯作者,作者还包括信息科学技术学院的博士后张燚鑫。该工作得到了国家自然科学基金委、安徽省科技厅和中国科学技术大学创新团队培育基金的资助。
论文地址:ICCV2023 Oral
代码地址:暂无