近日,中国科大视觉与多媒体研究组的研究团队在增量目标检测任务上取得新进展。通过在表征空间联合新旧类别进行对齐有效的实现了新旧知识的融合,并提出一种面向视觉语言模型的对应蒸馏方法来保持旧类语义结构的稳定。相关成果以“GCD: Advancing Vision-Language Models for Incremental Object Detection via Global Alignment and Correspondence Distillation”为题,将发表在AAAI 2025上。
在基于视觉语言模型(VLMs)的增量目标检测(IOD)方法研究中,研究人员发现,尽管现有的基于局部对齐的更新范式能够有效避免标签冲突,但在复杂的场景中,如COCO 2017等大规模数据集,仍然会表现出灾难性遗忘。更为严重的是,这种方法会导致表征空间阶段化,进而削弱了视觉语言表征的潜力,从而影响了增量目标检测任务的效果。
为了解决这一问题,研究人员对现有方法进行了深入的分析,发现灾难性遗忘的根本原因在于语义结构的崩溃。具体来说,旧知识缺乏足够的约束,且新知识的引入会导致旧类语义结构的崩溃,使得新旧知识的融合变得困难。我们进一步发现,传统的知识蒸馏方法虽然能够一定程度上缓解遗忘问题,但由于视觉语言模型在不同阶段之间存在天然的语义鸿沟,直接使用传统蒸馏方法会导致性能下降。
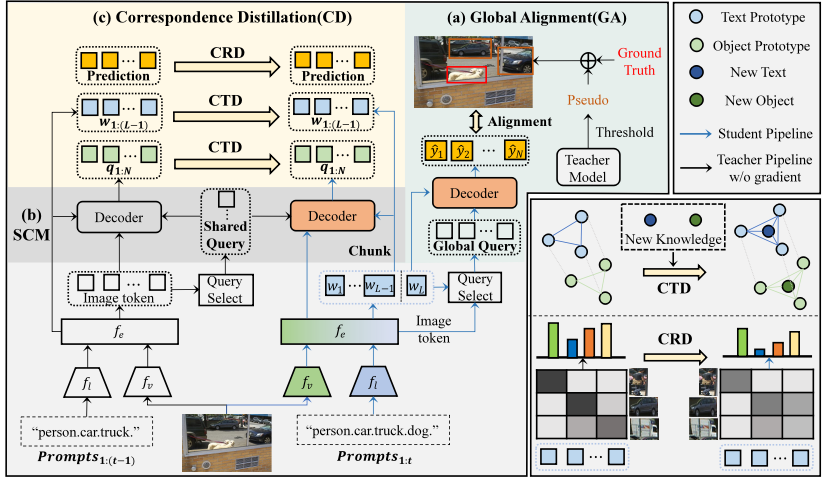
图1 方法流程图
为此,研究人员提出了一种新的方法来解决这一问题。首先,设计了一种全局对齐策略,能够有效地融合新旧知识,并在不同阶段之间保持统一的表征空间。在增量目标检测任务中,旧物体在后续场景中会再次出现,但由于缺乏标注,这些物体通常被忽略,甚至被视为背景。为此,充分挖掘当前场景中存在的旧知识,通过旧模型生成潜在物体的伪标签,并借助新旧知识的对比学习来构建全局一致的语义结构。此外,我们还提出了一种对应蒸馏方法。通过引入语义对应机制,确保新旧模型输出的一致性。通过对响应和特征两个层面进行蒸馏,有效保持弱势类别的响应稳定,并更好地维护旧类语义结构的稳定性。
大量实验结果表明,所提出的方法显著提升了增量目标检测的性能,发现了视觉语言模型增量更新过程中灾难性遗忘的原因,达到了最先进的水平,并提供了一个新的算法框架为进一步探索这一方向奠定了基础。
中国科学技术大学王子磊教授为该论文的通讯作者;信息科学技术学院的博士生王栩为该论文的第一作者,信息科学技术学院博士生林子涵为该论文的第三作者。
论文链接: 暂无
代码链接: https://github.com/Never-wx/GCD