近日,中国科学技术大学信息科学技术学院的王子磊教授在域适应语义分割研究方面取得了重要进展。其研究团队创新性地采用超像素级主动学习策略,以最小成本获取最具价值的标注数据,从而显著提升了域适应语义分割的效果。这项研究为域适应语义分割领域提供了新思路。相关成果以“Efficient Active Domain Adaptation for Semantic Segmentation by Selecting Information-rich Superpixels”为题,于2024年9月29日发表在国际顶级计算机视觉学术会议ECCV 2024 (Oral)上。
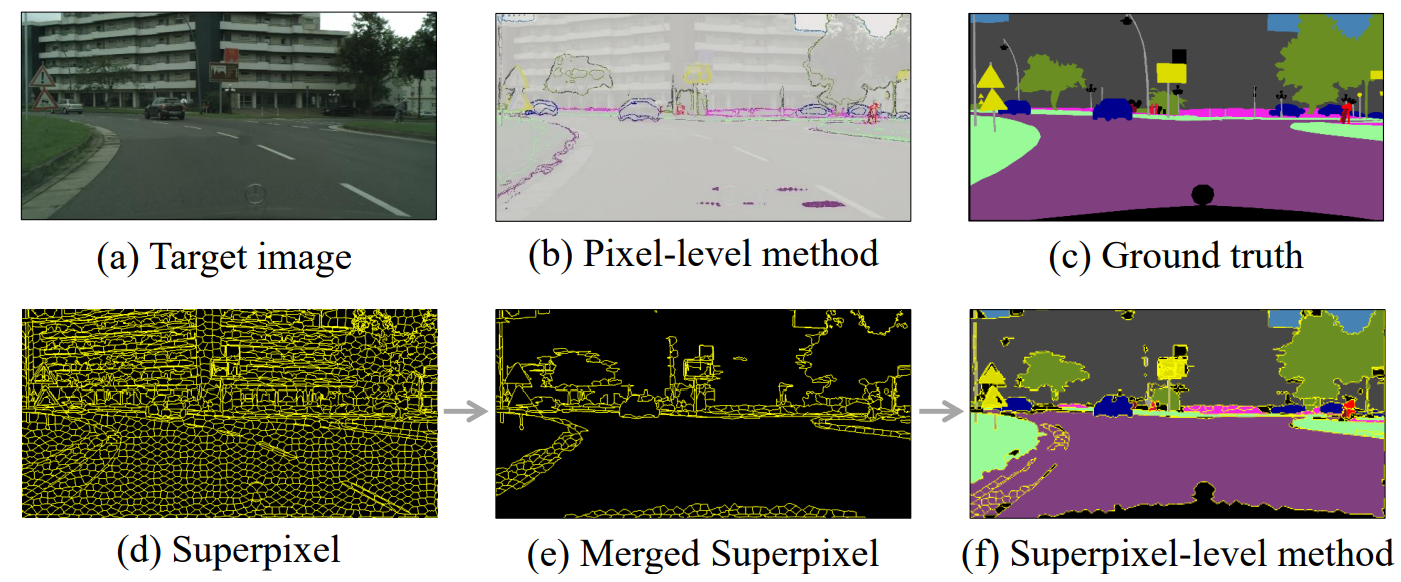
图1 主动域适应语义分割的标注方法
主动域适应语义分割通过利用已标注的源域数据,选择目标域中最具价值的少量数据进行标注,以提升模型在目标域上的语义分割性能。其关键在于如何有效地选择待标注的数据。现有的方法通常采用像素级标注,即独立选择像素点进行标注,这种方式往往需要为每张图像选取1万到2万个像素点才能达到较好的模型性能,导致标注成本高昂(如图1b)。为了解决这一问题,中国科学技术大学的王子磊教授及其VIM研究团队探索了超像素级标注方法(如图1d),并提出了利用超像素融合技术进一步降低成本、提高标注效率的方案(如图1e和1f)。该方案仅需对每张图像标注40到640个点就能实现超越像素级标注方法(标注1万到2万个点)的性能。
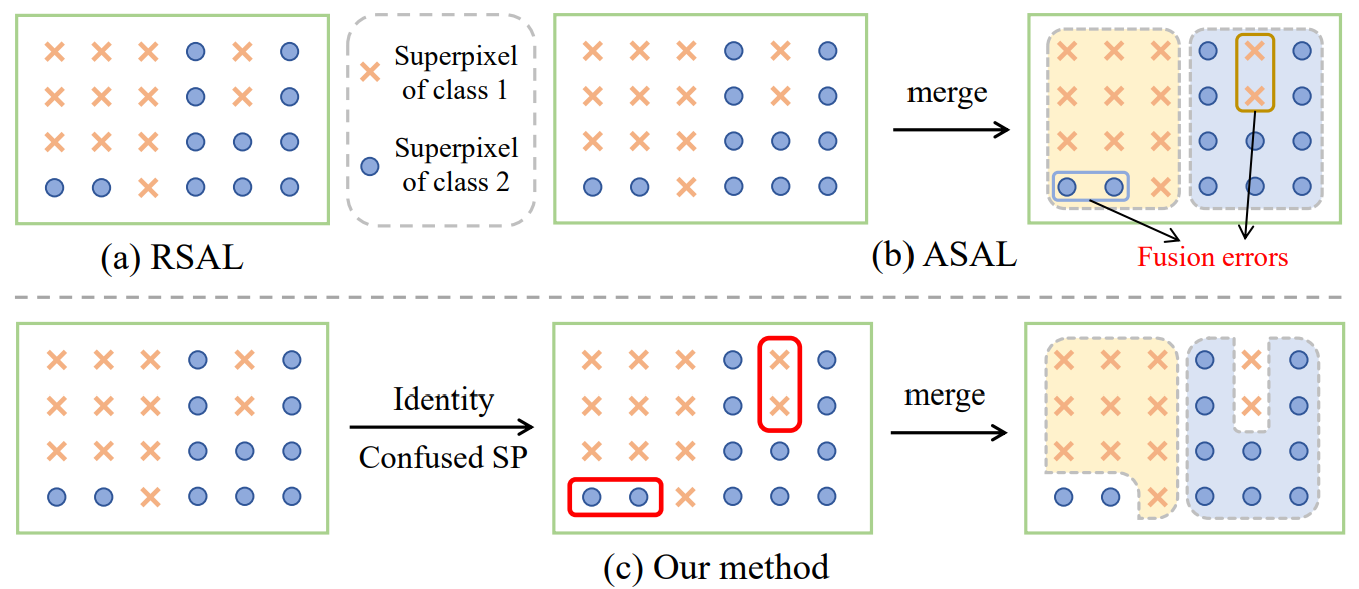
图2 超像素融合方法
超像素是指图像中具有相似属性(如颜色、纹理)的像素集合。由于超像素内部的像素属性相似,这意味着它们大概率属于同一语义类别,因此在标注时,只需为每个超像素分配一个语义类别即可标记其内部的所有像素,从而大幅降低标注成本。为了进一步提高标注效率,可以将特征相似的超像素进行融合。然而,在域适应设置下,由于源域与目标域之间存在域差异,源域模型提取的目标域特征容易产生混淆,即不同类别的特征可能会混在一起(如图2a)。在这种情况下,超像素的融合可能导致不同类别易混淆的超像素被错误地合并,进而导致最终的标注错误(如图2b)。为了解决这一问题,研究团队提出了基于不确定度的超像素融合方法,首先识别出易混淆的超像素,并在融合过程中排除这些超像素,从而提高标注的质量(如图2c)。

图3 方法流程
整体方法流程如下:首先,分别提取目标域图像的超像素和熵图。接着,根据熵图将超像素划分为高不确定度和低不确定度两类。然后,仅对低不确定度的超像素进行融合,而高不确定度的超像素则保持不变。融合后的超像素尺寸远大于未融合的超像素,因此在第一阶段,对所有经过融合的超像素进行标注。而在第二阶段,则使用剩余的标注预算,选择那些域差异最大的高不确定度超像素进行标注。
该研究有效地解决了当前方法标注成本过高的问题,并首次提出使用基于不确定度的超像素融合标注的方案,为主动域适应语义分割领域提供了新思路。
中国科学技术大学王子磊教授为该论文的通讯作者;信息科学技术学院的博士生高源为该论文的第一作者,人工智能研究院特任副研究员张燚鑫和信息科学技术学院博士生涂博海分别为该论文的第三、第四作者。
论文地址:暂无
代码地址:https://github.com/EdenHazardan/ADA_superpixel