近日,中国科大视觉与多媒体研究组的研究团队在基于视觉语言模型的通用域适应任务上取得进展。该研究团队发现,在通用域适应任务中,现有的基于聚类的方法往往受限于无法准确估计的聚类数量以及聚类中心的域偏移,导致了既复杂又不够鲁棒的算法设计。为此,该团队提出,通过在离散且富有语义意义的文本表征空间中优化聚类中心,从而构建简单且鲁棒的通用域适应算法。相关成果以“Target Semantics Clustering via Text Representations for Robust Universal Domain Adaptation”为题,将发表在国际会议AAAI 2025上。
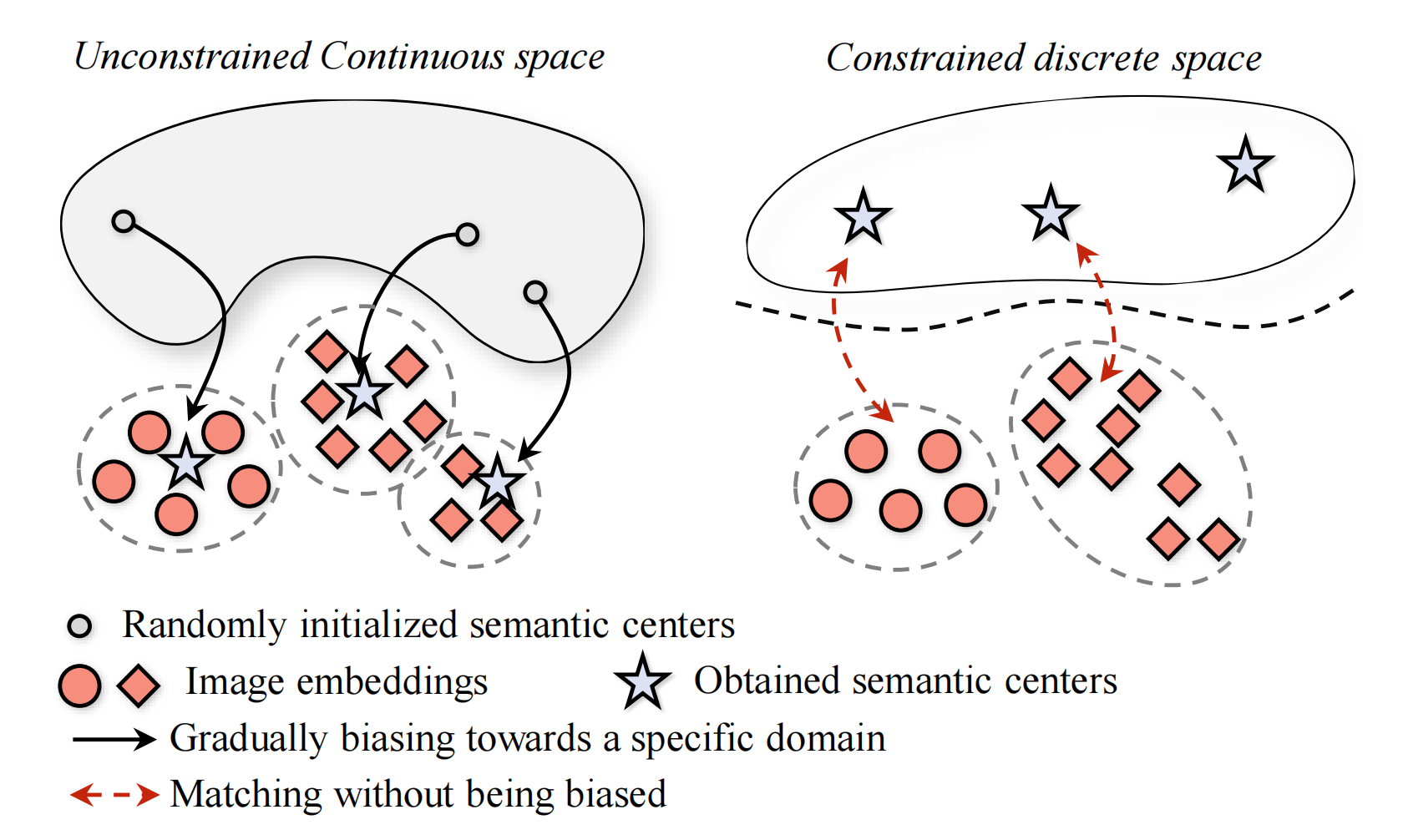
图1 方法原理示意图
域适应旨在利用易于获取标注的源域数据辅助模型适应到下游目标域。然而,实际应用场景中,由于标注的缺失,往往难以保证目标域与源域包含的类别一致,即存在类别偏移。对此,通用域适应旨在研究能够通用于各种类别偏移情况的域适应算法。针对这个任务,现有方法往往通过在不受约束的表征空间中执行聚类算法,并基于聚类中心匹配两域公共类。然而,由于聚类数量未知且聚类中心总是偏向特定域,现有算法往往十分复杂且无法鲁棒地应对不同域偏移情形。
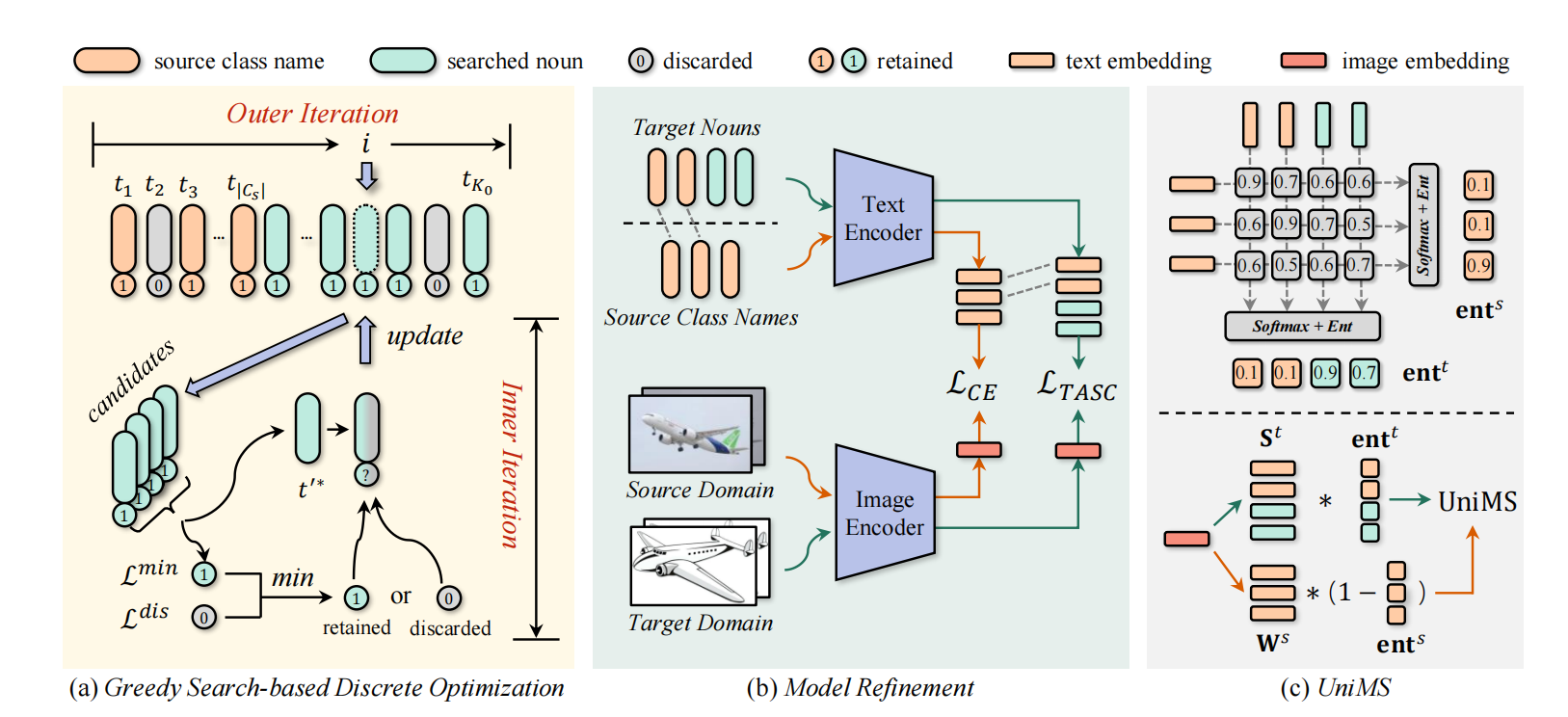
图2 方法流程示意图
针对这些问题,该工作在离散且富有语义意义的文本表征空间完成目标域语义聚类,从而构建了简单且鲁棒的通用域适应方法。这种特殊的受约束的表征空间确保了合适的语义粒度,实现了目标域语义类别数量的准确估计。另一方面,文本表征空间总是包含较少的域信息,从而大大简化了公共类匹配算法的设计。具体地,为了利用该表征空间,该工作将语义聚类形式化为一个以互信息极大化为目标的优化问题,并提出了两阶段的优化方法。第一阶段,模型从WordNet名词中通过贪心搜索对目标域进行语义级别的聚类,从而表征目标语义。第二阶段,使用源域和目标域数据进一步微调模型,使其适应特定目标场景。此外,该工作还提出了一种新颖的评分函数,专门用于通用域适应中的未知类判别。
该工作在四种常用的域适应基准以及四种不同的域偏移任务设置上对提出的方法进行了评估,大量的实验结果表明了基于文本表征空间的目标语义聚类算法更加有效并实现了最先进的性能。总的来说,作为一个算法框架,该工作的方法为后续通用域适应研究提供了一个简单且强大的基准。
我校信息科学技术学院自动化系博士生贺伟男为该论文第一作者,王子磊副教授为论文通讯作者,人工智能研究院副研究员张燚鑫为该论文的第三作者。
论文链接: 暂无
代码链接: https://github.com/Sapphire-356/TASC